本文是一篇内部的个人分享(已无敏感信息) ,目的是增加产品、开发同学对 LLM 的理解,以降低沟通中的阻力,更好推进落地。
以下经脱敏后的原文:
大模型并不神奇
很多人听到’大模型’这个词可能会觉得很神秘,其实,LLM 就是神经网络,只是很大的神经网络,相对传统神经网络,大就是它的特点。我们用一个压缩算法的简单例子来帮助理解这个巨大的神经网络。
原始的压缩算法
- • 原始数据
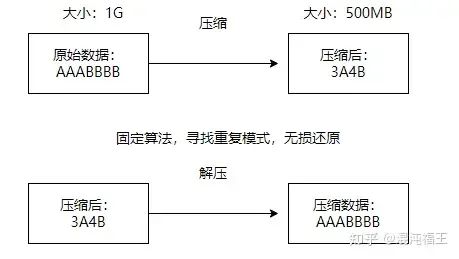
首先,我们来看一下传统的压缩算法。假设我们手头有一段原始数据:AAABBBB。这些数据在未压缩的情况下占用1GB的存储空间。
- • 压缩过程
接下来,压缩算法会使用固定的规则,寻找数据中的重复模式,比如这里的连续’A’和’B’。通过这种方式,压缩算法可以将AAABBBB压缩成一个更短的形式:3A4B。
- • 压缩后
这样一来,压缩后的数据仅占用500MB的存储空间。通过更短的字符表示原始的数据,我们大大减少了存储需求。
需要用这个数据的时候,也是固定的规则,把数据解压还原成 AAA BBBB
- • 压缩率
压缩算法的一个重要特点是速度快和但压缩率低。这个例子中,我们通过寻找和表示数据中的重复模式,大幅减少了数据的存储需求。这个比例通常不会很高,但却是无损的。
大模型的压缩
我们来看一下大模型的也是类似压缩过程。
- • 原始数据
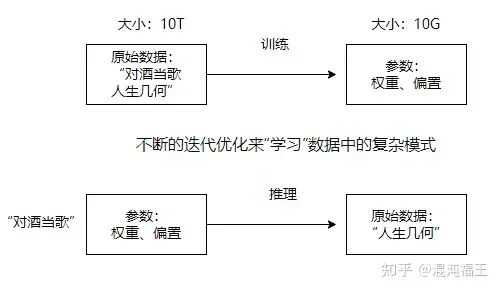
首先,我们有大量需要学习的数据。就像我们刚才提到的传统压缩算法,大模型在训练之前也需要处理大量的原始数据,它可能包含世界上大部分书籍,网络中数亿语料。假设在海量数据中,我们有一首诗“对酒当歌,人生几何”,这些全世界搜罗的各类文本总的一起可能占用高达10T的存储空间,比如 llama3 使用的预训练数据高达15T。
- • 压缩过程
然后,大模型通过训练,不断迭代优化、调整参数,从数据中“学习”各种复杂的模式。这个过程有点像我们前面提到的压缩算法,只不过大模型的压缩更加复杂和智能。它通过调整模型的参数——包括权重和偏置——来捕捉数据中的模式和规律。也就是上一页 ppt 提到的重复部分。
- • 压缩后
最终,我们得到了一个经过训练的模型,它只需要10GB的存储空间。这就像是我们从原始的10TB数据中提取出的“压缩”版本。这个压缩版本包含了所有重要的信息,以便模型能够高效地进行推理和预测。
- • 压缩率
值得注意的是,这种过程相对较慢,需要耗费大量的时间和计算资源,但压缩率非常高。
我们可以看到,一个 10T的预料,可能被压缩到一个 10G 大小的模型中。llama3 8b 就是一个非常稠密的模型。
LLM 不仅仅压缩了字符串
实际上,更重要的是它能够学习字符串之间的相关性,也就是抽象规律,甚至能够推理出原始数据中不存在的事物。
- • 抽象模式学习
我们来看一个例子。在训练过程中,大模型会学习大量类似的数据。例如,输入的数据可能包含“苏格拉底是人,人会死,苏格拉底会死”这样的句子。通过不断迭代优化,大模型能够学习到这些数据中的抽象模式,比如“三段论”这样的逻辑关系。
- • 训练过程
在这个过程中,大模型通过调整其参数——包括权重和偏置——来捕捉这些复杂的模式和规律。训练完成后,这些参数就固定下来,代表了模型对数据的理解。
- • 推理过程
经过训练后,大模型不仅能记住训练数据中的具体内容,还能根据学到的模式推理出新的信息。例如,当我们给模型输入“马顿是人,人会死”时,模型可以根据学到的模式推理出“马顿会死”这样的结论。但语聊中其实可以没有马顿这个人,你可以输入任何一个不存在,捏造的事物,让模型去推演这个模式,它能成功。
但模型的理解,和人类不一定一样,我们千万不要强行套用用人的模式,如果你把它带入太多人类思维,会失望。但如果你忽略掉模型学习到的特有能力,肯定会错过很多东西。这里有点玄学,没有理论,全都是实践出真知的结果。这个玄学的问题,即使是顶级的 AI 学者也是充满争议的,但不管怎么样,我们可以从实用主义出发解决工作的问题,包括我们后面讲的提示工程。
问题讨论
- • GPT采样的随机性
推理输出的结果是一个数学矩阵,理论上输入数据相同,参数不变的情况下,应该永远一样。但最终数学矩阵要转换成现实世界的真实文本。这一过程涉及到一些随机采样方法,使得每次生成的文本可能有所不同。
- • 贪心/波束算法
首先,我们来讲讲贪心算法。贪心算法会直接选择概率最高的词汇,这样可以保证每次输出都是一致的。然而,这种方法缺乏多样性,生成的文本可能显得单调。
gpt2 的出现,直接让更随机的采用方式,变成了 SOTA 业界最佳水平。后面随机采样成了主流,这一做法到底是不是最佳实践,也是有争议的,有人认为波束算法的问题还是数据训练国产导致的。
- • 温度缩放
接下来是温度缩放。温度参数决定了生成文本的多样性。温度越低,logit向量会被压缩得越尖锐,高概率的词汇更容易被选择。0温度相当于退化成贪心算法。温度越高,生成的文本越随机,适合生成更加丰富多样的内容。
- • top-k 采样
最后是 top-k 采样。这种方法限制了词汇表的选择范围,只从概率最高的k个词中进行选择。k值越大,选择空间越多,生成的文本也就越不确定。
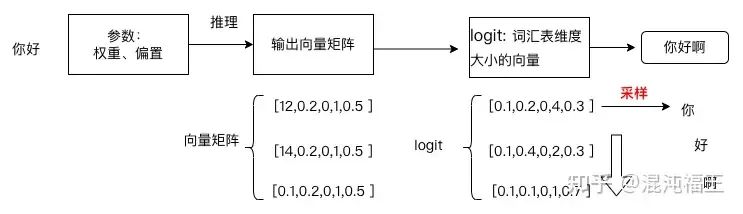
在这个过程中,模型会根据输入生成一个输出向量矩阵。这个矩阵通过logit转换后,再映射到词汇表,生成可能的词汇。通过不同的采样策略,比如温度缩放和top-k,我们可以得到不同的输出文本。
 简易版 gpt 推理
简易版 gpt 推理
这里我想表达的是,训练后参数是固定的,在推理环节只是做矩阵乘法,相同输入,的推理的中间数学输出是确定的, 不存在随机和概率问题。
我们看到的不确定性是来源于输出矩阵转现实世界文本的最后环节,刻意设计了一个概率选词算法,原因仅仅这样效果,文本更流畅。模型的内在知识不存在不确定性。
之前的其他算法比如贪心算法,波束算法等效果不佳,openai 在 gpt2 中使用问题和 top-k 获得了更好效果。仅仅是目前的一个工程实践。
提示工程 is all your need
这个梗借用了 Attention Is All You Need。对于我们的大部分应用场景, 提示工程几乎是唯一的选择。
少量的业务知识,比如只是几百几千的内容,给到足够上下文是成本最低,性价比最高的方案。
微调通常只适合大量垂直且固有的业务知识。针对特定场景,在基础模型上微调,会让通用能力下降,这个是已知的问题。这种又叫遗忘性灾难,后面的数据会对前面学到的知识产生影响。除非你的数据足够大,足够优质,抵消对原始能力的损失。
微调且无法快速适应业务知识变化, 对于我们的大部分场景是投入产出比非常低的事情。
精心构造提示词
首先,通过精心构造提示词,我们可以更好地还原被压缩的数据中的相关性。
一次性输出的局限性
其次,模型的一次性输出往往只提供有限的知识。
这里想表达的是,模型是认识这个世界的相关性,提示工程就是去挖掘和利用这个数据相关性。
且模型训练的上下文有限,意味着学习到的相关性是有限的,通过工程化组合可以解决这个问题。
这个工作的价值并不会随着模型性能提高而没有用,三个诸葛亮还是比三个臭皮匠厉害。提示工程不会因为底层模型能力的提高,而失效,相反会让应用场景性能变得更好。
一个分层
就好像用 typescript 语言很容易学,你可以很快用它写一个 hello word。
但也用 typescript 语言搭建复杂的工程系统工程不简单。vscode 这个软件就是一个基于 typescript 构建的大型工程。
提示工程类似。自然语言提示词虽然很容易学,可以快速写一个翻译指令。但搭建一个基于 LLM 的复杂的人机交互工程并不容易。
L1提示工程-问答
一问一答,一个具体任务由一次模型回答解决。
我本来是想以『简单提示工程』作为副标题,但这些一问一答的提示工程『不能算简单』,而是最底层。关于提示工程技巧,我们不展开,大家从去年一年应该都接受过各种信息。我们要看这种提示工程的落地场景。
常见应用落地场景:
聊天,翻译,代码生成,文字总结。
充当双语词典:“请充当帮助用户学习的词典,把用户给你的内容翻译成中文,给出发音、词语解释、双语示例和词源”。
目前调研的大部分英语学习软件都接入了llm,在 openai chatgpt3.5 刚刚出来的时候甚至出现过纯 llm 组成的英语学习软件,整个站点功能全部由大模型提示词组成。每个不同的模块就是一个独立的提示词,这种软件在 gpt 出现后大量涌现,极大的降低的英语软件的开发成本。
L2 提示工程-组合
有时候任务很复杂,一个问题来回解决不了,或者解决的效果很差,怎么办。
想象我们解决一个问题,如果你直接灵感爆发,可以张口而来,比如:【这个需求还不容易,就这么定了】~。结局很可能是导致大大的延期,并且和产品预期不符合。
可以更理性的思考方式:这个需求需要哪些同学参与,涉及哪些工具,我应该选择和谁合作?这个思路对吗,然后我分别再按这些思路尝试。复杂的提示工程也是这样的。
我们可与把大模型假设成一个被关在房间里的人。假设每次这个人都会忘记之前说的话。每次你只能给它一个问题,并且可以带上之前的历史内容。
就这样: 精心构造提示词、通过 N个问题,让模型模拟人类推理和行动的过程。
来让我们来看应该典型的向模型多次提问方式。
将设我们的任务是让大模型『帮忙生成四大银行的最近 3 年的贷款利率,并生成图表』。我们可以下面一系列提示词组合。
这个场景我们假定每次都是独立的向模型提一个请求,同时假定有程序逻辑处理中介过程,但可以忽略细节。
2.1第一个提示词:
从现在开始你充当一个专家,你拥有调用不同工具的权限,每个工具都由它的作用,你必须模拟像人类一样思考。下面是你拥有的工具列表:搜索引擎:可以调用网络查询事实内容,参数是查询的“关键” 字。图表生成:可以生成各种图统计图标,你需要把数据按 xx 格式给它。
每次收到用户的问题,你都需要先思考,再采取行动。以如下格式返回:思考:我应该如何做这件事情呢,仔细思考它。
行动:我应该采取的方式是什么,可以调用其中的工具
观察:采取行动后观察到的结果是什么。
… … 你应该不断循环以上步骤,直到你认为最终完成任务
最终答案:……
【注:… 有 5 次调用细节,字太多,中间已省略……】
可以发现我们 5 次独立的调用模型,最终完成了这个任务。这里的核心点是什么呢?我们运用提示词技巧,让模型模拟人一样的思考方式,给出行动轨迹,程序再识别行动轨迹,最终得到结果。这实际上就是所谓的 reAct 技术简化版介绍,R 代码推理,A代表路径,就是让模型自己推理,生成路径。实际的情况会更复杂,我们不展开讨论。
我们看到了提示工程不仅仅是简单的提问,还可以把多个问题有巧妙的组合起来,让模型解决问题。这是大模型能够影响显示世界,变成强大生产力的关键。人类现实世界有大量的工作、任务、决策经验都是由文本记在案,而模型正好通过训练学习到了这些文字续写的能力,我们反过来加以利用,就变成了经验复用。
L2 类应用的场景由很多,比如 RAG 信息检索、图表生成、PPT 生成、复杂任务等,任何尝试使用外部工具调用来增强 LLM 能力的都可以使用此类提示工程技术。
L3提示工程-架构
 贴一个海外基于大模型做各种生态工具的图。
贴一个海外基于大模型做各种生态工具的图。
我们刚刚已经聊到 L2 级别的提示工程是可以通过多次提问,不断诱导模型生成解决问题的路径,对于一个问题的解决可能需要重复调用很多次才能完成。
试想下,如果一种更复杂的现实世界任务,比如请完成产品的这个需求,需求链接如下…要求完成编码,并通过测试,将代码 push 到仓库。
这样的一个任务对于人类而言都是有挑战的,它通过设计需求理解,git 仓库拉去,代码编写,测试用例编写,流水线部署,发布等研发流程。
如果我们继续尝试用上面的这种 reAct 方案,会发现要完成这项工作,可能准备几十个工具,并且把每个工具调用的推理、行动路径拼接到模型上下文,将会极大影响模型性能。
在 LLM 实践中,人们发现,即使是非常强的模型,让它一次专注理解并处理一个简单的任务,效果更佳。
为了解决这个问题,将一项复杂的工作,拆分成不同的模块,每个模块由一个独立的模型去解决,**每个模型都拥有独立的上下文、并配置自己专属的工具。这些模型最终通过一个中介代理转发,这种模式就叫 Agent **。
Agent 可以代理更精细的模型分工,提示词可以对每个模块,甚至每次微小任务进行独立优化设计,reAct 只是被其使用的一种局部的技术而已。这样导致的问题则是调用会消耗更多 token,一项复杂的工作,可能会调用几十次,甚至上百次的 LLM 。
我为什么要把 Agent 作为提示工程标题一部呢?我要强调的是 虽然涉及 Agent 模型微调,以速度优化,但在不考虑响应速度的背景下,Agent 工程大部分工作将是围绕提示工程及其组合优化进行。
我们今天不会介绍 Agent 细节,Agent 有各种各样的架构组合,业界和学术界的方案也层出不穷,大家可以基于兴趣自行探索。
L3 提示工程——性能案例
SWE-bench 是一个基准测试,用于评估从 GitHub 收集的真实软件问题上的大型语言模型。词比基于纯 gpt4 高出好几倍。
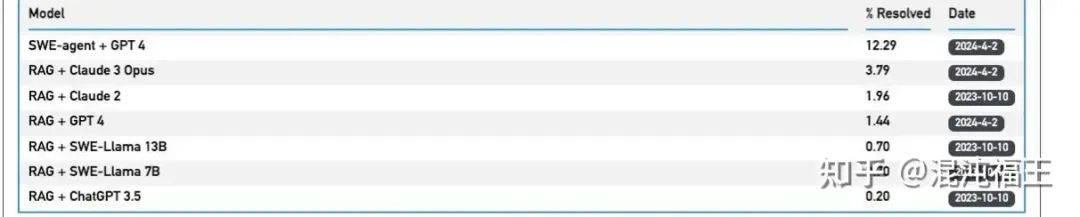
容易点
- • 快速原型:大模型再复杂的调用都是一条一条 LLM api 组成,快速原型不复杂。我们很多原型都能在基本甚至半天搞定。
- • 有大量工具可以辅助:从开发者视角,到小白视角,有大量工具可以辅助。
 这是我之前一个调研,可参考历史博文
这是我之前一个调研,可参考历史博文
——除 langchain 外,任何复杂的 L3 级别的构建都不推荐使用这类工具,因为 L3 架构需要大量定制化调优,而这类工具通常是有自己的一套逻辑。
挑战点
提示词优化
提示词优化需要找到足够多的案例,才能反馈出你的效果 ,这里是需要花大量时间才能逐步提高。虽然有自动提示词这种工具,但想要达到不错的仍然是看人类专家。
组件交互
假设每个微小的提示词调整好了,组成成为一个更大的整体系统, 我们可能会效果不佳,因为每个局部的提示词是独立的。必需考虑到全局的效果。这种全局的效果调整,非常消耗时间和 token 资源。
效果优化
可以用 20% 的时间快速构建 80% 的功能,但必须花剩下 80的时间来提高剩下 20% 的效果。这里其就是我们上面讲的点,在不考虑效果,确实可以用20% 的时间,搭建个 77,88,但最终是需要花 80%的时间,才能让系统正常上线的。这里可以借鉴 linkedin 经验,他们花了1 个月快速出 demo ,但最终耗时 6 个月才大规模面向用户。
里面很多细节,比如为了让大模型更好理解接口,他们把全部的接口设计成给人类用的,和给大模型用的,后者面向大模型更友好,然后再这两者之间建立映射。
还有,比如我们的 json 解析通常会由于模型返回的格式不标准而异常,linkedin 编写一个非常巨大函数的把能够想得到的全部异常格式自动修复,做防御性解析。最终让解析报错率从5 % 降低到 0.005% ,极大的减少了重试的次数。
反馈评估
如果没有自动化工具评估,整个 LLM 工程系统很难得到最终反馈,我们目前大多靠人肉和用户反馈调研。
性能优化:
这里一个是底层的 LLM 响应优化,目前最主要的就是量化,缓存,gpu 加速,我们会设计比较少。
另一个应用层,可以通过流式、缓存、提示工程,及交互等提高体验。
举个流式例子:比如还有阿里钉钉为了可以让返回的 json 可以提前渲染前端 UI 组件,采用了流式提前解析, 在 json 没有完全返回的情况就进行自动补全, 渲染出 UI 轮廓和部分数据。
提示工程也和性能相关,因为不同的提示词,返回的 token 数量不一样,消耗的时间也会与差异。这里 linkedin 有一个有趣的例子。他们尝试在一些场景深度使用 COT 上线后,由于用户量大,马上带来了机器负载问题。反正,调整后,负载发生了变化。
当然,这些场景主要是面向海量 C 端用户需要采取的措施,我们内部工具系统可以酌情考虑,根据用户反馈和实际需要来做。
对于我们而言,目前最大的困难点还是在前面 3 个点。也是最基础和不可忽略的提示工程调优。
没有金科玉律
在结尾,我们来再次分享一个个人的想法,大模型、特别是工程化和应用场景落地是当下非常新的东西。
我们没有太多过去的经验,业界的标准和方案都不断在更新迭代,以至于它没有像传统行业那样太多的最佳实践可以参考和指导,不存在 java 最佳实践、前端最佳实践,也没有经典的 24 种设计模式。一切都是全新的。
这对我们而言既是挑战,也是机遇,我们并不需要被目前的这些已有技术优化、产品形态等思维约束,特别是提示工程,这里没有金科玉律。在将大模型技术和产品结合起来的路上,每个人都可以提出自己新的想法、去尝试新的方案,这能让自身和行业都得到繁荣和和发展。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。